
✅ 배열이란?
배열은 같은 타입의 원소들을 효율적으로 관리 할 수 있는 기본 자료형이다. 같은 타입의 변수가 여러 개 필요할 경우 자주 사용한다.
배열은 하나의 변수 이름으로 동일한 타입의 데이터를 그룹화하여 관리할 수 있고, 인덱스를 사용하여 원하는 데이터에 임의 접근할 수 있다는 장점을 가지고 있다.
1. 배열 선언
배열 선언에 대해 알아보자. 더 이해하기 쉽게 코드로 보는게 편할 것 같다.
// 배열 내 원소 {1, 2, 3, 4, 5}를 가지며 크기가 5인 배열 선언
int arr1[] = {1, 2, 3, 4, 5};
// 처음 두 원소만 1, 2로 초기화하고 나머지는 0으로 초기화, 크기는 5
int arr2[5] = {1, 2}; // {1, 2, 0, 0, 0}
// 배열 내 원소를 모두 0으로 초기화하고 크기가 5인 배열 선언
int arr3[5] = {}; // {0, 0, 0, 0, 0}
// 초기화 없이 선언
int arr4[5]; // 배열 내 원소는 초기화를 해주지 않았기 때문에 쓰레기 값 출력.선언하는 방법은 위와 같이 여러가지 방법이 있다. 다만 여기서 3번째 0으로 모두 초기화의 경우 C++이 아닌 C의 경우는
int arr3[5] = {0}; 으로 해줘야 에러가 나지 않는 것으로 알고 있으니 참고하길 바란다.
2. 배열과 차원
배열은 2차원 배열, 3차원 배열과 같이 다차원 배열을 사용할 때도 많다. 하지만 컴퓨터의 메모리 구조는 1차원이므로 다차원 배열도 실제로 1차원 공간에 저장이 된다 즉, 배열은 차원과는 무관하게 메모리에 연속 할당된다.
✔️ 배열의 접근 및 제어
배열로 선언한 변수들은 메모리의 연속된 공간에 할당된다. 따라서 다음의 그림을 보면 배열의 원소 간 주소값은 변수 크기만큼 차이난다. 예를 들어, 정수형(int)이면 4byte씩 차이가 난다. 실수형(double)의 경우는 8byte씩 차이가 난다.
변수명 앞에 &를 붙이면 해당 변수의 주소값을 연산할 수 있다. 다음 코드를 보자. intArray라는 변수로 크기가 3이고 {1, 2, 3}으로 초기화한 배열을 선언했다.
int intArray[3] = {1, 2, 3];
&intArray[0]; // 0x7ffeeef7a8c0
&intArray[1]; // 0x7ffeeef7a8c4
&intArray[2]; // 0x7ffeeef7a8c8
intArray를 그림으로 그려보면 아래 그림과 같다.

이렇게 메모리 주소가 연속적이라는 특징이 있어 배열은 인덱스를 활용하여 특정 원소에 임의 접근할 수 있다.
(아 참고로 배열의 인덱스는 우리가 아는 1부터 시작이 아닌 0부터 시작이라는 것을 잊지말자!!)
✔️ 2차원 배열
2차원 배열의 코드를 살펴보자. 2차원 배열은 행렬로 보면 쉽다. 아래와 같이 arr는 결국 2행 3열의 행렬이다.
int arr[2][3] = {{1, 2, 3}, {4, 5, 6}};
/* 사람이 보기 쉽게 표현한 그림
열0 열1 열2
행0 [ 1 2 3 ]
행1 [ 4 5 6 ]
*/
이를 그림으로 나타내면 다음과 같다.
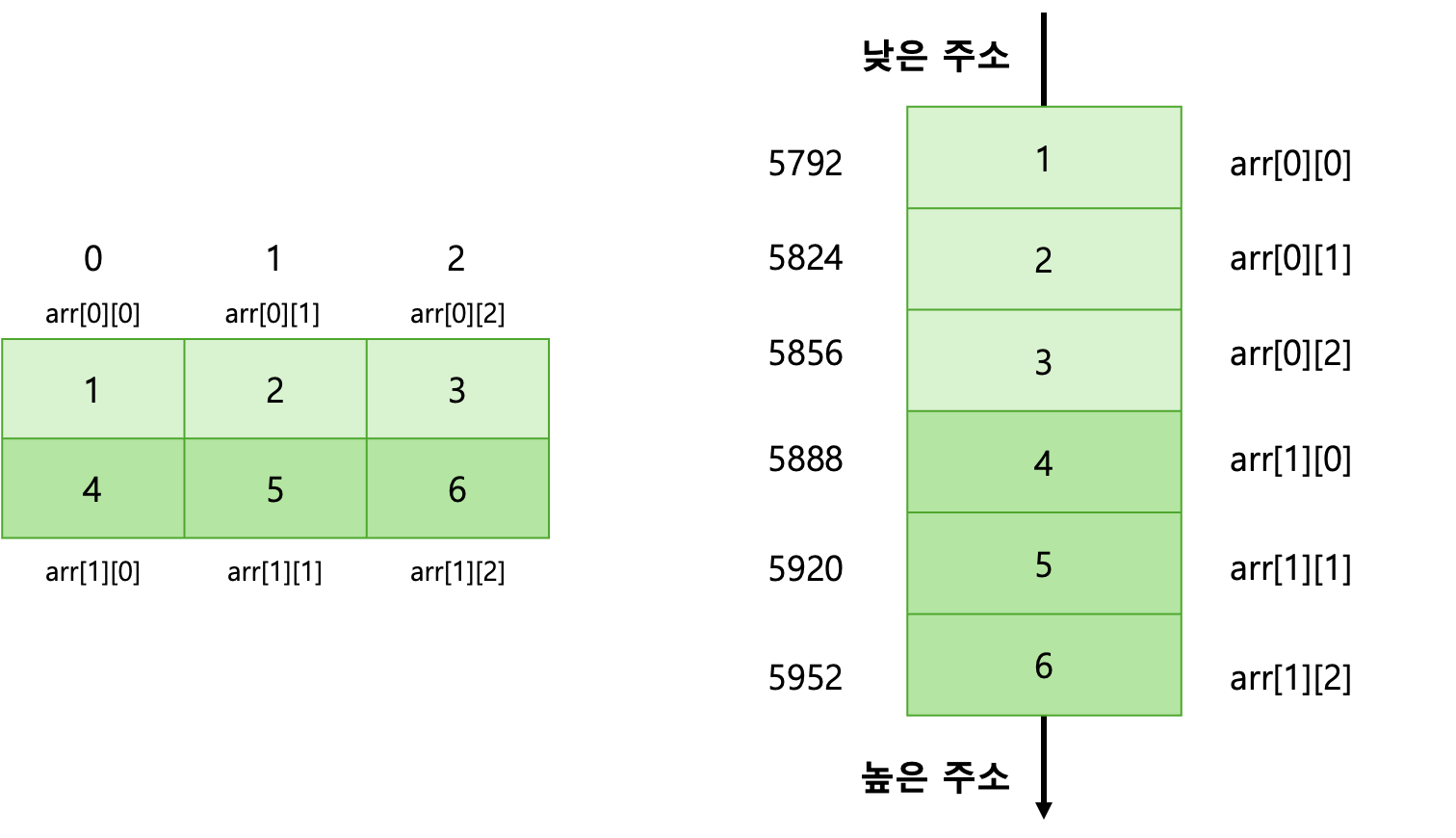
왼쪽은 2차원 배열을 사람이 이해하기 쉽도록 표현한 것이다. 오른쪽은 실제 메모리에 저장된 구조이다.
이 배열의 특성을 잘 기억해두자.
✅ 배열이 효율성
1. 배열의 시간 복잡도
배열은 임의 접근이라는 방법으로 배열의 모든 위치에 있는 데이터에 단 한번에 접근 할 수 있다. 따라서 시간 복잡도는 O(1)이다. 배열은 데이터를 어디에 저장하느냐에 따라 추가 연산에 따라 시간 복잡도가 달라진다.
✔️ 맨 뒤에 삽입할 경우
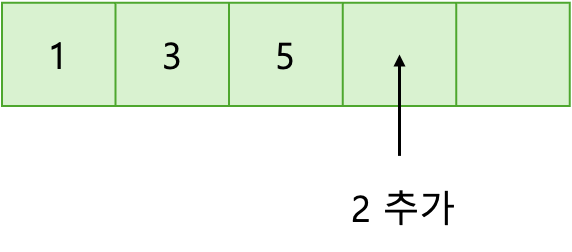
위의 그림처럼 배열의 맨 뒤에 2를 추가하자고 하자. 데이터를 바로 임의 접근이 가능하고 데이터를 삽입해도 다른 데이터의 영향을 끼치지 않는다. 따라서 시간 복잡도는 O(1)이다.
✔️ 맨 앞에 삽입할 경우

데이터를 맨 앞에 삽입한다면 위와 같이 기존 데이터들을 뒤로 한 칸 씩 밀려야한다. 이 경우 연산에 대한 비용이 필요하다. 데이터 개수를 N개로 한다면 시간 복잡도는 O(N)이 된다.
✔️ 중간에 삽입할 경우
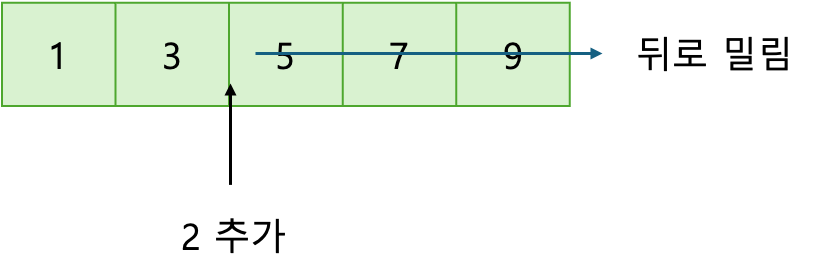
그렇다면 중간에 삽입할 경우는 어떨까? 위의 그림처럼 5앞에 2를 추가하게 되면 5이후의 데이터는 모두 뒤로 밀리게 된다. 즉, 현재 삽입한 데이터 뒤에 있는 데이터 개수만큼 미는 연산을 해야 한다. 밀어야 하는 데이터 개수가 N개라면, 이것 또한 시간복잡도는 O(N)이 된다.
2. 배열을 선택할 때 고려할 점
프로그래밍을 하다보면 어떤 자료구조를 써야 할지 고민이 된다. 배열은 가장 기본적이면서도 강력하다. 하지만 단점도 분명히 있다.
배열의 경우 데이터 추가, 삭제에 드는 비용이 많이 든다. 그래서 배열로 데이터를 저장하기 전에는 항상 이런 비용을 생각하고 문제를 풀어야 한다.
그러면 배열을 선택할 때 어떤 점을 고려해야 할까?
데이터에 자주 접근하거나 읽어야하는 경우 배열을 사용하면 좋은 성능을 낼 수 있다. 그래프나 행렬을 표현 할 때 배열을 활용하면 좋지만 단점으로는 메모리 공간을 충분히 확보해야 하는 단점도 있다.
그래서 다음과 같은 두 가지 사항을 고려해 배열을 선택하자.
- 할당 할 수있는 메모리 크기를 확인하자. (메모리는 충분한가?)- 배열로 표현하려는 데이터가 너무 많으면 런타임에서 에러가 난다.
보통 정수형 1차원 배열은 1000만 개, 2차원 배열은 3000*3000 크기를 최대로 생각하자. 문제에서 입력, 출력 제한사항을 잘 확인하자. - 중간에 데이터 삽입이 많은지 확인하자.- 배열은 선형 자료구조이기 때문에 중간이나 처음에 데이터를 자주 삽입하게 되면 시간 복잡도가 높아져 시간 초과가 발생한다.
가끔 문제를 보면 입력에 "길이는 100을 넘지 않는다"라는 문장을 본적이 있을 것이다. 이 경우 애초에 다음과 같이 배열을 할당하는 것도 에러가 안나도록 하는 방법인 것 같다.
int arr[100];
하지만 보통 코딩테스트에서는 정적 배열보다는 STL의 동적인 Vector를 주로 사용한다!!!!!!!!! 개념은 그래도 꼭 알아두어야 한다.
[출처] 코딩 테스트 합격자 되기 C++ 편 - 저자 박경록에서 인용
'C++ 코딩테스트 준비' 카테고리의 다른 글
| [1주차] 코딩 테스트 합격자 되기 C++ (코딩테스트 문법) - part 2 (3) | 2025.06.15 |
|---|---|
| [1주차] 코딩 테스트 합격자 되기 C++ (코딩테스트 문법) - part 1 (9) | 2025.06.14 |