
ASCII 코드의 등장 배경
컴퓨터는 우리가 말하는 알파벳 a, b, c 등을 알지 못합니다.
그래서 예를 들어, a는 1이고 b는 2다 라는 것을 입력해줘야 합니다.
그런데 여기서 문제는 어떠한 기준이 없기 때문에 어떤 컴퓨터는 a를 2라고 표현하고 어떤 컴퓨터는 a를 1이라고 표현하게 되면서 글자가 깨지게 됩니다.
따라서, 문자를 숫자로 표현할 수 있도록 정해진 '약속(표준)'을 만들었습니다.
이 '약속'이 ASCII(아스키코드/American Standard Code for Information Interchange)입니다.
총 128개의 부호로 정의되어 있으며,
알파벳 대문자 A는 10진수 기준으로 65, 알파벳 B는 66으로 되어있습니다.(소문자 a는 97, b는 98)

아래에서 좀 더 자세히 다루겠습니다.
( **ASCII 코드 문자표 참고** )

ASCII 인코딩 표준
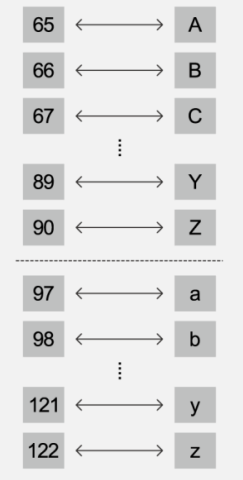
ASCII 코드는 컴퓨터가 텍스트 데이터를 저장하기 위해 흔하게 사용하는 표준코드체계입니다. 이 표준에서 숫자 65는 대문자 'A'와 대응됩니다.
따라서,
컴퓨터가 대문자 'A'를 저장하고 싶다면 숫자 65를 이진수로 저장할 것입니다.
65를 이진수로 표현하게 되면
26x1 + 25x0 + 24x0 + 23x0 + 22x0 + 2x0 + 1x1 = 64+1로 표현할 수 있습니다. 즉, A를 2진법으로 표현하면 1000001입니다.
그다음의 숫자들은 옆의 그림처럼 다른 대문자와 쭉 대응됩니다.
소문자도 ASCII에서 숫자로 나타낼 수 있습니다. 소문자 'a'는 숫자 97로 나타내고 'b'는 98로 나타내며 그 후 다른 소문자들도 마찬가지입니다.
따라서, 컴퓨터가 소문자 'a'를 저장하려면 대문자와 마찬가지로 숫자 97을 2진수, 1100001로 저장해야 합니다.
여기서 소문자 'a'와 대문자 'A'가 25의 자릿수만 다르다는 것을 알 수 있으실 겁니다.
즉, ASCII 코드에서 소문자는 같은 대문자와 항상 25만큼 큽니다.
결과적으로 이진수에서 25의 자릿수만 바꿔주면 되기 때문에
(소문자는 1, 대문자는 0으로) 소문자와 대문자 간의 변환이 쉬워집니다.
이해가 덜 되시는 분을 위해서 사진으로 보여드리면


파란색 음영처리가 돼있는 부분을 보시면 이해가 가실 겁니다.
(소문자는 1, 대문자는 0)
ASCII의 한계
기본 ASCII 코드표는 7비트만 이용해서 모든 문자들을 나타냅니다.
이것은 ASCII코드로 27개, 즉 128개의 문자를 나타낼 수 있다는 것입니다.
확장 ASCII는 8번째 비트를 추가하여 총 256개의 문자를 나타낼 수 있습니다. 하지만 8비트 ASCII 코드로도 나타낼 수
없는 문자들이 아직도 많이 있습니다. 우리가 사용할 수 있는 문자들의 개수는 256개보다 훨씬 더 많기 때문입니다.
이 때문에 생긴 것이 훨씬 더 많은 문자들을 포함할 수 있는 유니코드(Unicode)가 생기게 됐습니다.
출처 : 부스트 코스 CS50 코칭 스터디 2기 https://www.boostcourse.org/cs112
모두를 위한 컴퓨터 과학 (CS50 2019)
부스트코스 무료 강의
www.boostcourse.org
참고 : 아스키코드와 유니코드 velog.io/@kim-jaemin420/ASCII-Unicode-%EC%95%84% EC% 8A% A4% ED%82% A4% EC% BD%94% EB%93% 9C% EC%99%80-%EC% 9C% A0% EB% 8B%88% EC% BD%94% EB%93%9C
ASCII & Unicode (아스키코드와 유니코드)
컴퓨터는 어떻게 자료를 표현할까? 컴푸터가 정보를 표현하기 위한 기본 원리는 전기신호이다. 전기신호가 있으면 '1', 없으면 '0' 두 가지 경우로 정보를 표현한다. 이 '0'과 '1'을 데이터의 최소
velog.io
'CS50' 카테고리의 다른 글
| 비트(bit)와 바이트(byte) 란? (0) | 2021.02.11 |
|---|---|
| 2진법이란? (0) | 2021.02.10 |
| 컴퓨팅 사고력이란 무엇일까? (0) | 2021.02.10 |